
|
Training, Open Source Programming Languages |
| Home | Accessibility | Courses | The Mouth | Resources | Site Map | About Us | Contact |
| For 2023 (and 2024 ...) - we are now fully retired from IT training. We have made many, many friends over 25 years of teaching about Python, Tcl, Perl, PHP, Lua, Java, C and C++ - and MySQL, Linux and Solaris/SunOS too. Our training notes are now very much out of date, but due to upward compatability most of our examples remain operational and even relevant ad you are welcome to make us if them "as seen" and at your own risk. Lisa and I (Graham) now live in what was our training centre in Melksham - happy to meet with former delegates here - but do check ahead before coming round. We are far from inactive - rather, enjoying the times that we are retired but still healthy enough in mind and body to be active! I am also active in many other area and still look after a lot of web sites - you can find an index ((here)) |
|
Loading and saving data - Python / numpy
If you're using big data sets in Python, you're probably using the numpy module - providing you with fast data handlers at C speed of running, and Python coding speed. But how do you load that data in? Numpy also provides a number of data handlers, data setup routines, and also a save and restore capability. There's a very basic example at [link] where I've generated a numpy object from text (I could have used a file ...) - each row and column in the incoming text string has been placed into a row or column in the numpy array. I've added a further example too ... 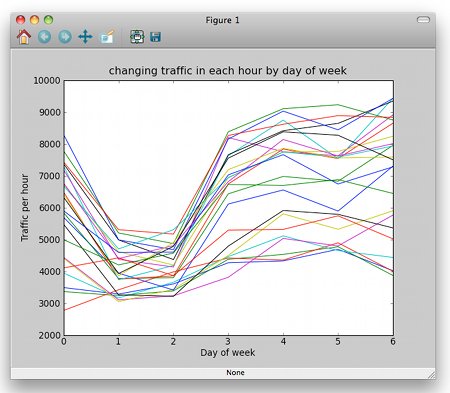 Our daily server log file comprises about 150,000 access records (so it's 30Mb to 40Mb in size) and I wanted to see how the traffic varies in each hour through the week via a graph. So that means that I needed to go through and find a piece of information from around a million records, spread over around a quarter of a gigabyte of data to get the results shown on the right. Python's quite mpressive even without numpy - that analysis took less than 10 seconds on my laptop, but later I'll be doing the same exercise to average out the data for a whole six months, and the time will start to get serious. Our daily server log file comprises about 150,000 access records (so it's 30Mb to 40Mb in size) and I wanted to see how the traffic varies in each hour through the week via a graph. So that means that I needed to go through and find a piece of information from around a million records, spread over around a quarter of a gigabyte of data to get the results shown on the right. Python's quite mpressive even without numpy - that analysis took less than 10 seconds on my laptop, but later I'll be doing the same exercise to average out the data for a whole six months, and the time will start to get serious.Numpy's save and load functions allowed me to dump out my array to a file, and to load it back in again - my 10 seconds drops to less that 1 second if I do this for a week of data (and for six months it would drop me from about four minutes down to 1 second!). The code to convert my Python list in which I did the counting (that's another numpy extra feature) is: info = np.asarray(counter)and the code to save the data to file is: np.save("logweek.npy",info)When I came to run the program (again), I simply had it check if the file existed and if it did, I loaded it: if os.path.exists("logweek.npy"):The complete source code example is [here] ... note that it also uses matplotlib - a plotting library that's often used in association with numpy and scipy If you're looking to save pure Python data, have a look at the Pickle and Marshall modules that are a part of the standard distribution ... or the cPickle module which is implemented in C and much quicker; this latter becomes the standard in Python 3. We have various examples around - [marshall example] and a [post on pickling]. (written 2010-10-09) Associated topics are indexed as below, or enter http://melksh.am/nnnn for individual articles Y118 - Python - numpy, scipy and matplotlib[2990] What are numpy and scipy? - (2010-10-09) [2992] Matplotlib - graphing in Python - teaching examples - (2010-10-10) [2993] Arrays v Lists - what is the difference, why use one or the other - (2010-10-10) [2997] 3D graphics - web site usage - simple matplotlib and python example - (2010-10-12) [3554] Learning more about our web site - and learning how to learn about yours - (2011-12-17) [4440] A first graph with Matplotlib in Python - (2015-02-22) [4445] Graphing presentations in Python - huge data, numpy and matplotlib - (2015-02-28)
Some other Articles
A river in Melksham is not just for boaters.Python - some common questions answered in code examples Loading and saving data - Python / numpy Oddballs in Plymouth Not mugged in London! Memorial to a day in 1999 Python dictionaries - reaching to new uses |
4759 posts, page by page
Link to page ... 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96 at 50 posts per pageThis is a page archived from The Horse's Mouth at http://www.wellho.net/horse/ - the diary and writings of Graham Ellis. Every attempt was made to provide current information at the time the page was written, but things do move forward in our business - new software releases, price changes, new techniques. Please check back via our main site for current courses, prices, versions, etc - any mention of a price in "The Horse's Mouth" cannot be taken as an offer to supply at that price.
Link to Ezine home page (for reading).
Link to Blogging home page (to add comments).
PH: 01144 1225 708225 • EMAIL: info@wellho.net • WEB: http://www.wellho.net • SKYPE: wellho
PAGE: http://www.wellho.net/mouth/2991_Loa ... numpy.html • PAGE BUILT: Sun Oct 11 16:07:41 2020 • BUILD SYSTEM: JelliaJamb